
Deep Learning Demystified: What Product People Actually Need to Know About Neural Networks


Every product leader I know is making decisions about AI features right now: which capabilities to build, where to invest, and how to evaluate what's real versus what's hype. And yet, I don't think the vast majority of product people know what's going on behind the scenes of modern AI–how it actually works under the hood.
You don't need to be able to build a neural network from scratch. But if you're making product decisions about AI, you need a working mental model of what these systems actually do. Otherwise, you're driving a car without knowing where the steering wheel ends and the gas pedal begins. You'll make it somewhere, but probably not where you intended.
So let's fix that. Here's your no-nonsense guide to deep learning, neural networks, and the key mechanisms that power them. Explained for people who build products, not people who build models.
What Is a Neural Network, Really?
At its core, a neural network is a system that learns patterns from data. That's it. But the how is where it gets interesting.
Think of it like this: imagine you're training a new hire to review customer support tickets and route them to the right team. On day one, they're guessing. They read a ticket about a billing error and send it to engineering. Wrong. You correct them. They read another ticket about a login issue and send it to billing. Wrong again. You correct them. Over hundreds of tickets, they start picking up on the signals: certain words, phrases, and patterns that indicate which team should handle it.
A neural network does exactly this, but at a scale and speed no human could match. It takes in data, makes predictions, gets told how wrong it was, and adjusts. Over and over, millions of times, until the predictions get good.
The Building Blocks: Nodes, Layers, and Weights
Let's break down the actual machinery.
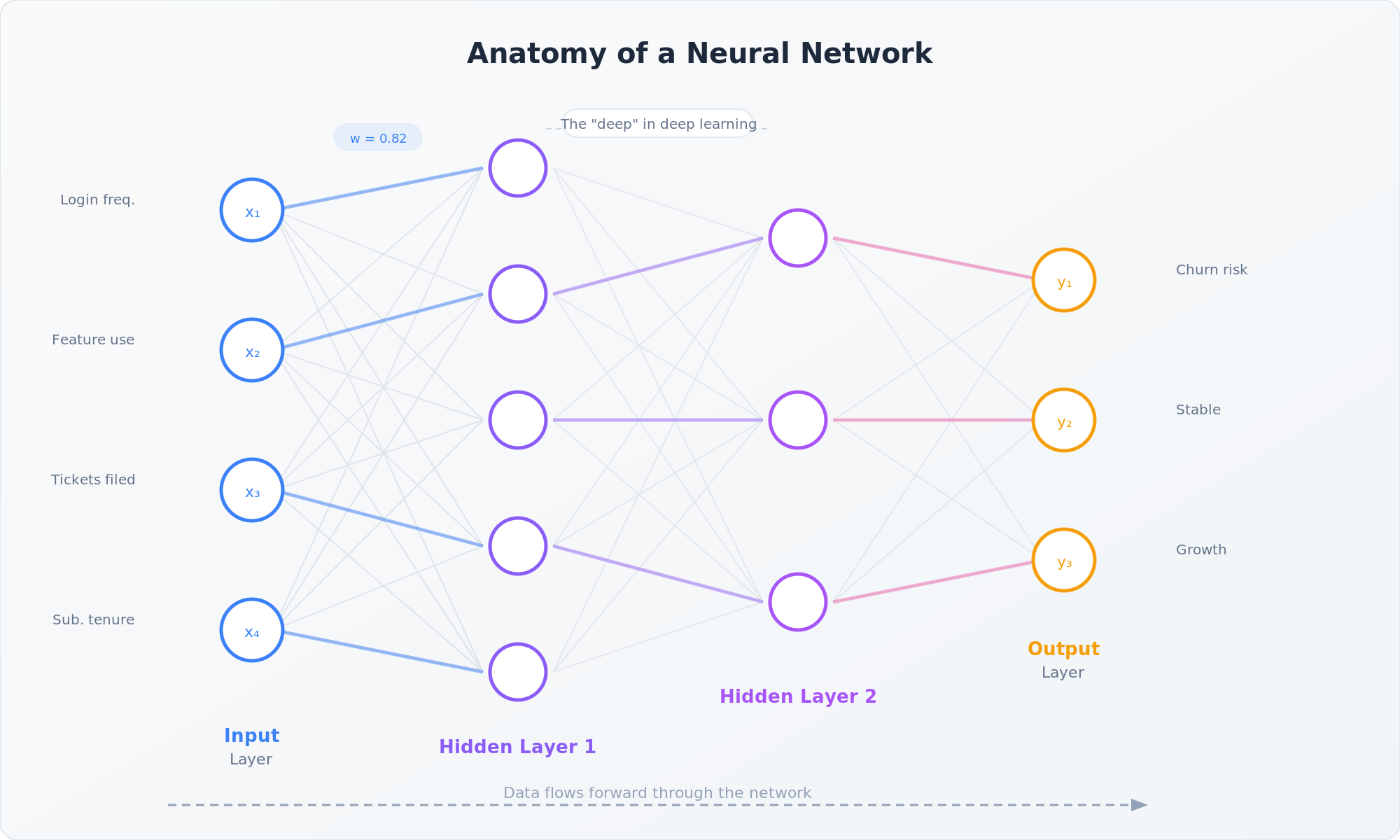
A neural network is made up of nodes (sometimes called neurons), organized into layers. There are three types of layers that matter:
Input layer. This is where data enters the network. If you're building a model that predicts whether a user will churn, the input layer might receive data points like login frequency, feature usage, support tickets filed, and subscription tenure. Each data point gets its own node.
Hidden layers. This is where the magic happens. These layers sit between input and output, and they're where the network learns to identify complex patterns. Each node in a hidden layer takes the inputs from the previous layer, applies a mathematical transformation, and passes the result forward. One hidden layer might learn simple patterns (e.g., "users who log in less often tend to churn"). Deeper layers combine those simple patterns into more complex ones (e.g., "users who log in less often AND file support tickets AND are in their first 90 days are very likely to churn"). This is the "deep" in deep learning: multiple hidden layers stacked on top of each other, each one building more abstract representations of the data.
Output layer. This is the network's answer. For a churn prediction model, this might be a single node that outputs a probability between 0 and 1. For a model that classifies support tickets into categories, you'd have one output node per category.
Connecting all these nodes are weights: numerical values that determine how much influence one node has on the next. Think of weights like volume knobs. When the network is first initialized, these weights are essentially random. The entire process of training a neural network is about tuning these weights until the network's predictions are accurate.
How the Network Learns: Forward Pass and Loss
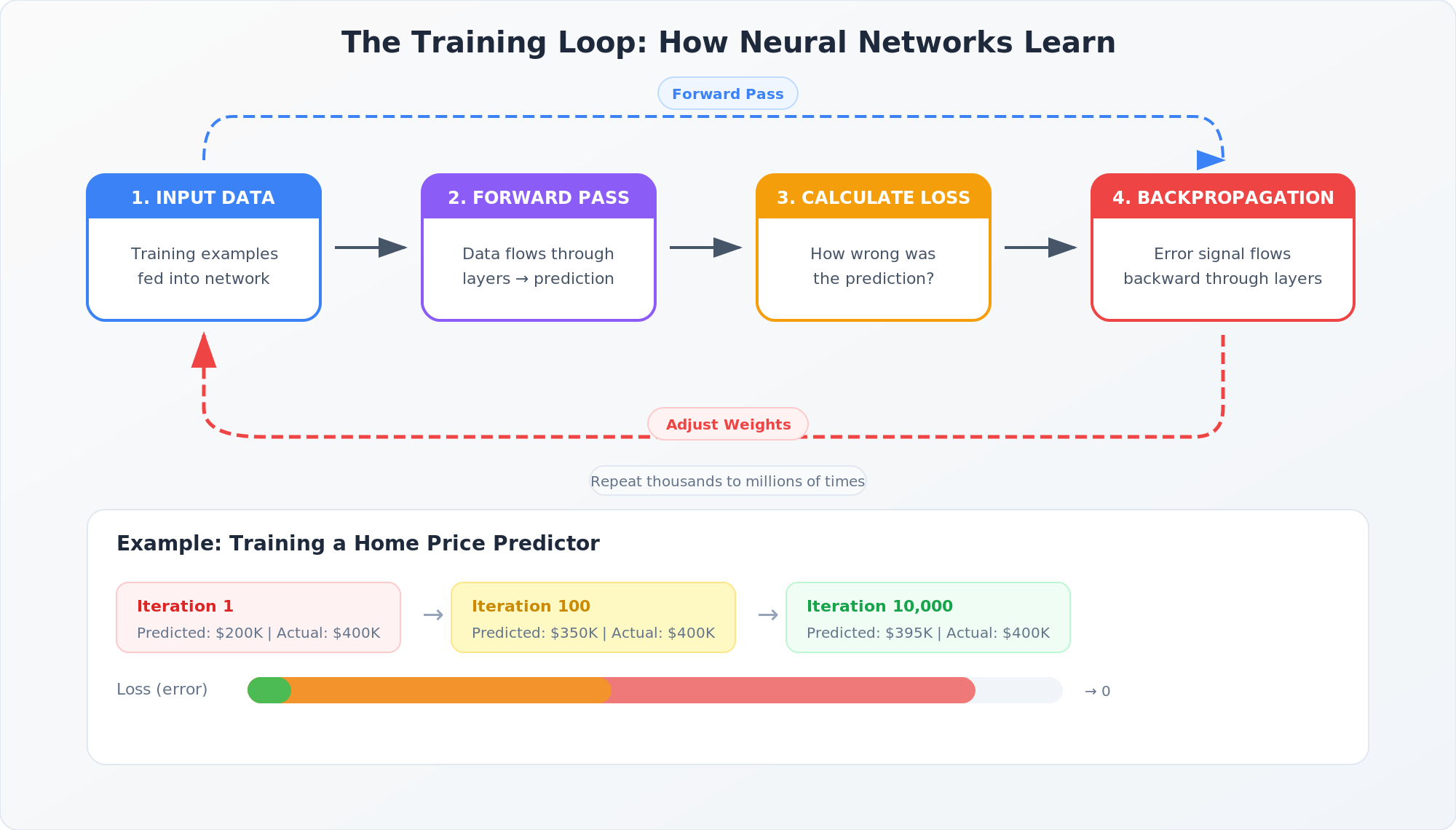
Here's where it comes together. When you feed data into a trained neural network, it flows through the layers in what's called a forward pass. Each node takes its inputs, multiplies them by the weights, adds them up, applies a mathematical function (called an activation function, which helps the network learn non-linear patterns), and passes the result to the next layer. At the end, you get a prediction.
But during training, that prediction is usually wrong, especially early on. So the network needs a way to measure how wrong. That's where the loss function comes in. The loss function compares the network's prediction to the actual correct answer and produces a number that represents the error. A high loss means the prediction was way off. A low loss means it was close.
Here's a concrete example. Say you're training a model to predict home prices. The network predicts a house is worth $350,000, but the actual sale price was $400,000. The loss function calculates that $50,000 gap and turns it into a signal the network can use to improve.
Backpropagation: The Engine of Learning
This is the mechanism that makes neural networks actually work, and it's more intuitive than it sounds.
Once the network has made a prediction and calculated the loss, it needs to figure out which weights to adjust and by how much. It does this through backpropagation, which literally propagates the error signal backward through the network, from the output layer back to the input layer.
Think of it like post-mortem analysis after a product launch that didn't hit its targets. You start with the outcome (we missed our activation goal), then work backward through the chain: Was the onboarding flow the issue? Was it the messaging? The targeting? The feature set? Each factor contributed some amount to the miss, and you want to adjust the ones that had the biggest impact.
Backpropagation does exactly this, but mathematically. It calculates how much each weight in the network contributed to the error, then nudges each weight in the direction that would reduce that error. The size of the nudge is controlled by something called the learning rate. Too big and the network overshoots; too small and it takes forever to learn.
This cycle (forward pass, calculate loss, backpropagate, adjust weights) repeats thousands or millions of times across the training data. Gradually, the weights settle into values that produce accurate predictions. That's training.
Three Ways Neural Networks Learn
Everything I've walked through so far (forward pass, loss, backpropagation) describes how a network improves. But there are different paradigms for what it's improving against. Think of these as three different teaching styles, each suited to different problems.
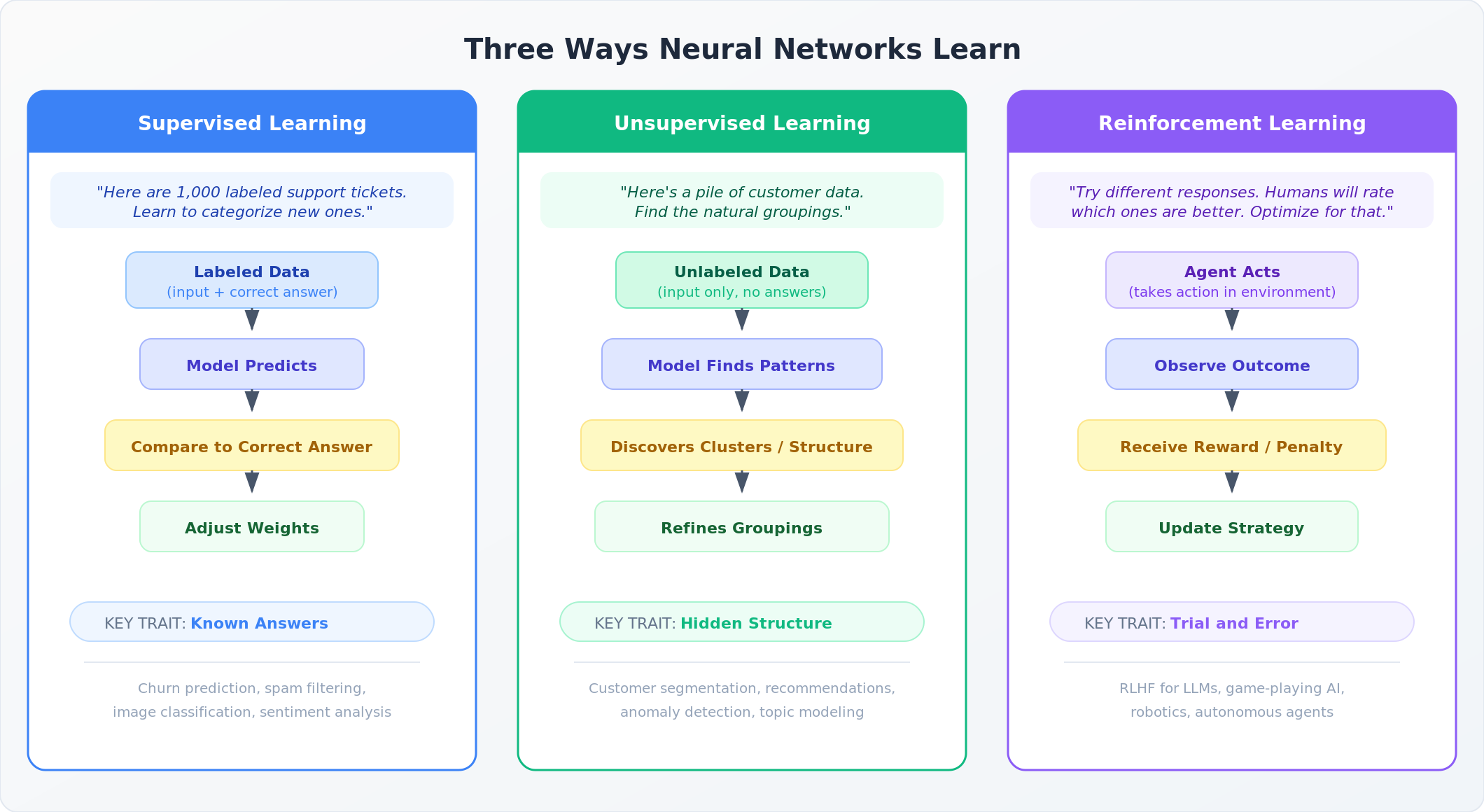
Supervised Learning: Learning from Labeled Examples
This is what we've been discussing. You give the network a dataset where every input has a known correct answer, and it learns to map one to the other. The support ticket routing example from earlier is supervised learning: here's the ticket text (input), here's the correct team (label), now learn the pattern.
Supervised learning powers a huge share of the AI features you encounter as a product person. Churn prediction, spam filtering, image classification, sentiment analysis. Anywhere you have historical data with known outcomes, supervised learning is likely the approach.
The catch? You need labeled data, and getting high-quality labels can be expensive and time-consuming. If you've ever sat through a conversation about annotation pipelines or labeling vendors, this is why.
Unsupervised Learning: Finding Structure Without Answers
Unsupervised learning flips the script. Instead of giving the network labeled examples, you hand it a pile of raw data and say "find the patterns." There are no correct answers to learn from. The network discovers structure on its own.
Think about how you might organize a messy closet. Nobody hands you a label for each item. You naturally start grouping things: shirts here, pants there, winter gear in the back. You're finding clusters and categories based on the properties of the items themselves.
Unsupervised learning does the same thing with data. Common techniques include clustering (grouping similar data points together) and dimensionality reduction (simplifying complex data while preserving its essential structure).
This matters for product people more than you might think. Customer segmentation, recommendation engines, anomaly detection, and topic modeling are all powered by unsupervised learning. When Spotify groups listeners into taste profiles or when your fraud detection system flags an unusual transaction, unsupervised learning is often doing the heavy lifting. If your product has a "customers like you also bought" feature or an anomaly alert, there's a good chance unsupervised learning is involved.
Reinforcement Learning: Learning from Trial and Error
Reinforcement learning (RL) takes a fundamentally different approach from both supervised and unsupervised learning. Instead of learning from a dataset at all, an RL agent learns by taking actions in an environment and receiving rewards or penalties based on the outcomes.
The easiest analogy? Think about how you learned to ride a bike. Nobody gave you a dataset of "correct" cycling positions to study. Instead, you got on the bike, fell over, adjusted, fell over differently, adjusted again, and eventually figured it out through trial and error. The "reward" was staying upright. The "penalty" was hitting the pavement (or, perhaps more rarely but true in my case, the electrical box in our neighborhood).
In AI, reinforcement learning works the same way. An agent takes an action, observes the result, receives a reward signal (positive or negative), and adjusts its strategy accordingly. Over many iterations, it learns which actions lead to better outcomes.
This matters enormously for product people because of a technique called Reinforcement Learning from Human Feedback (RLHF). This is a key ingredient in how models like ChatGPT, Claude, and Gemini get fine-tuned to be helpful and safe. The process works roughly like this: the model generates multiple responses to a prompt, human evaluators rank which responses are better, and those rankings become the reward signal that trains the model to produce responses humans prefer.
RLHF is why modern AI assistants feel qualitatively different from raw language models. It's the layer of training that takes a model from "can predict the next word" to "can have a useful conversation." And it's directly relevant to any product leader evaluating AI capabilities, because the quality of the RLHF process has a massive impact on how the model behaves in your product.
A Few More Concepts Worth Knowing
There are a handful of other terms that come up constantly in AI product discussions, and having a basic grasp of them will make you a sharper participant in those conversations.
Training data is the dataset the model learns from. The quality, size, and representativeness of training data directly impacts what the model can and can't do well. If your training data has biases, your model will have biases. If your training data doesn't include examples of a particular scenario, the model will struggle with that scenario. As a product person, asking "what was this trained on?" is one of the most important questions you can raise.
Test/eval set is a separate chunk of data the model never sees during training, used purely to measure how well it actually performs. Think of it like a final exam with questions the student hasn't practiced on. If your eval set is too similar to the training data, you'll get inflated confidence in a model that falls apart in the real world. If it doesn't reflect your actual users and use cases, your metrics will lie to you. As a product person, asking "what's in our eval set?" matters just as much as asking what the model was trained on, because that's what's grading the homework.
Overfitting is when a model learns the training data too well. It memorizes specific examples rather than learning generalizable patterns. It's like a PM who's so focused on one customer's feedback that they build features only that customer needs. The model performs great on training data and poorly on anything new. This is why models are evaluated on data they haven't seen before, and why your ML team obsesses over test sets and validation metrics.
Transfer learning is the practice of taking a model that was trained on a massive general dataset and fine-tuning it for a specific use case. This is why you don't need millions of examples to build a useful AI feature. You can start with a pre-trained foundation model (from OpenAI, Anthropic, or others) and adapt it to your domain with a much smaller dataset. Understanding this changes the build-versus-buy calculus significantly.
Inference is the term for when a trained model makes predictions on new data. Training is the learning phase; inference is the doing phase. When a user interacts with an AI feature in your product, that's inference. And inference has real costs. Compute isn't free, which is why pricing models for AI products are evolving toward usage-based approaches.
Why This Matters for Product People
You might be thinking: "Interesting, but I have an ML team for this. Why do I need to know how the sausage gets made?"
Because these concepts directly shape product decisions.
When your team tells you a model "needs more training data," understanding the relationship between training data and model performance helps you prioritize data collection as a product investment, not just an engineering task. When you're evaluating whether to build a custom model or use an API, understanding transfer learning changes the conversation. When you're setting expectations with stakeholders about AI feature accuracy, understanding overfitting helps you explain why 99% accuracy on a demo doesn't mean 99% accuracy in production.
And when you're thinking about the next wave of AI products (agentic systems, autonomous workflows, AI that takes actions on behalf of users), understanding reinforcement learning gives you a foundation for reasoning about how these systems learn, improve, and sometimes fail.
Product leaders don't need to train models. But they need to speak the language well enough to make good decisions, ask the right questions, and bridge the gap between what the technology can do and what users actually need.
The most effective AI product leaders I know aren't the ones with the deepest technical knowledge. They're the ones who understand just enough to have the right instincts about what to build, how to evaluate it, and when to push back. This is your foundation for that.



