
How LLMs Actually Work: A Product Leader's Guide to the Tech Behind the Chat Box


In the last post, we cracked open the black box of neural networks. Nodes, layers, weights, backpropagation — the fundamental machinery that powers deep learning. If you missed it, go read that first. Everything in this post builds on that foundation. An LLM is a neural network — a very specific, very large neural network designed to work with language. The principles are the same. The architecture is where things get interesting.
Now we're going to tackle the thing you're actually using every day: large language models.
You're probably interacting with LLMs more than any other AI technology right now. Drafting emails, summarizing documents, brainstorming product strategy, writing SQL queries. Most users know LLMs are "predicting the next word," but that's like saying a car "burns fuel and moves." Technically true, deeply incomplete.
If you're making decisions about where and how to integrate LLMs into your product, "predicting the next word" isn't enough. You need to understand the mechanisms well enough to reason about what these models are good at, where they break down, why they're vastly more capable than initially thought, and why they behave the way they do.
So let's get into it. Here's how LLMs actually work, explained for the people building products with them.
Step One: Turning Words Into Numbers
Here's the first problem you need to solve if you want a neural network to work with language: neural networks only understand numbers. They can't process the word "churn" or the phrase "quarterly business review." Everything needs to be converted into numerical form before the network can touch it.
This happens in two stages, and both matter for product decisions more than you'd think.
Tokenization is the process of breaking text into smaller chunks called tokens. Tokens aren't always whole words. The word "understanding" might become two tokens: "understand" and "ing." A common word like "the" is a single token. A technical term your users throw around might get split into three or four pieces.
Why does this matter to you as a PM? Because LLMs have a finite number of tokens they can process at once (more on that later), and because you're often paying per token when using an API. That "simple" prompt your feature sends might be 500 tokens. The document your user wants summarized might be 50,000. Tokenization is where cost and capability constraints start to become real product decisions.
Embeddings are where it gets genuinely cool. Once text is broken into tokens, each token gets converted into a vector (a long list of numbers that represents that token's meaning in a multi-dimensional space). But not just any numbers. These vectors are learned during training, and they capture semantic relationships.
Here's what that means in practice: in embedding space, the vectors for "king" and "queen" are close together. The vectors for "king" and "refrigerator" are far apart. Even more interesting, the direction from "king" to "queen" is similar to the direction from "man" to "woman." The model has learned that these words relate to each other in a specific, meaningful way without anyone explicitly programming those relationships.
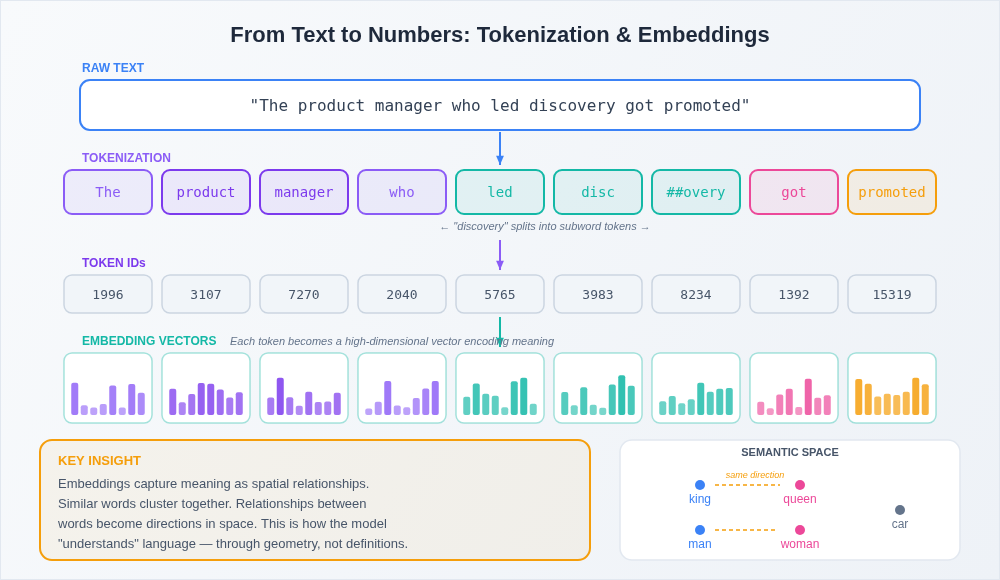
Think of it like a product org chart, but for meaning. Words that play similar roles in similar contexts end up in similar positions. And this spatial representation of meaning is what allows the model to generalize. It doesn't just memorize "king is related to queen." It learns the pattern of relationship, which it can then apply to words it hasn't seen in that exact combination before.
The Transformer: The Architecture That Changed Everything
Now we get to the big one. Everything we covered in the first post about neural networks (layers, weights, forward passes) is all still true of LLMs. But LLMs use a specific architecture called the transformer, and it's the reason language AI went from "kind of neat" to "this changes everything" starting around 2017.
The key innovation in transformers is a mechanism called self-attention, and it solves a problem that plagued earlier approaches to language AI.
Here's the problem: language is full of long-range dependencies. Consider this sentence: "The product manager who joined the team last quarter and has been leading the discovery work on the new onboarding flow just got promoted." The word "promoted" relates to "product manager" — but there are 20 words between them. Earlier neural network architectures processed language sequentially, word by word, and they were terrible at maintaining these long-distance connections. By the time the network reached "promoted," it had largely forgotten about "product manager."
Self-attention fixes this by letting the model look at every word in a passage simultaneously and figure out which words are most relevant to each other. When the model processes "promoted," it can directly attend to "product manager" regardless of how many words sit between them. It assigns an attention weight to every other word in the sequence — high attention to "product manager" and "leading the discovery work," low attention to "last quarter" and "the."
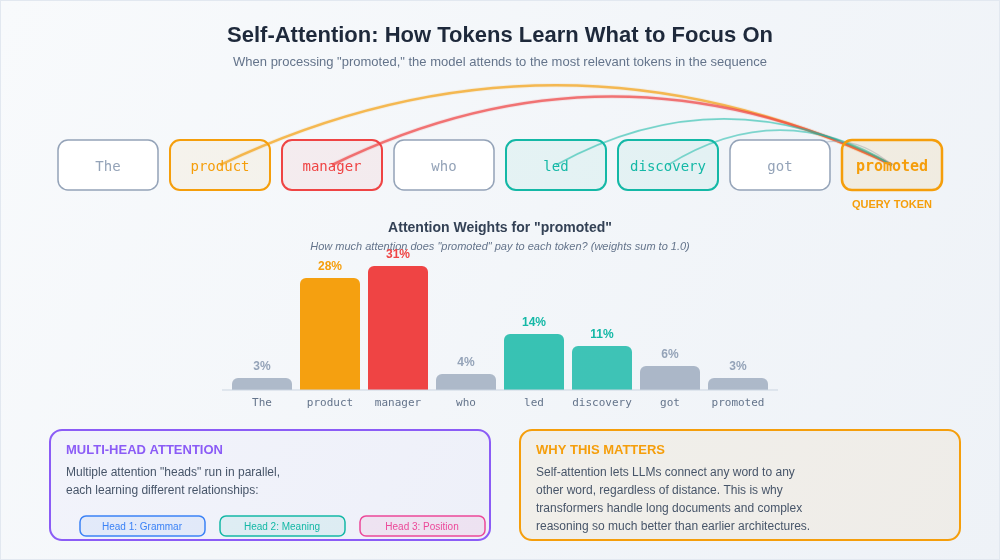
Think of it like being in a meeting where everyone's talking. A good PM doesn't process the conversation linearly. They're constantly connecting what the engineer just said to what the designer mentioned twenty minutes ago. They're weighting which pieces of information are relevant to the current discussion and which are background noise. Self-attention does this for every single token in the input, simultaneously.
And here's the key: the model learns what to pay attention to through training. Nobody programs rules like "job titles are important for promotion-related sentences." The model figures out these relevance patterns by seeing billions of examples of how language works. This is what those weight adjustments from backpropagation are actually tuning — the model's ability to decide what's relevant to what.
Transformers don't just have one attention mechanism but instead use multi-head attention, which means multiple attention patterns running in parallel. One head might focus on grammatical relationships. Another might track semantic meaning. Another might capture positional relationships. It's like having multiple team members on a customer discovery call, each tracking a different dimension of the conversation, then combining their notes into a richer understanding than any single perspective could produce.
Pre-Training: Learning From the Internet
So you've got this transformer architecture with its attention mechanism. Now you need to train it. And this is where the "large" in "large language model" starts to come in.
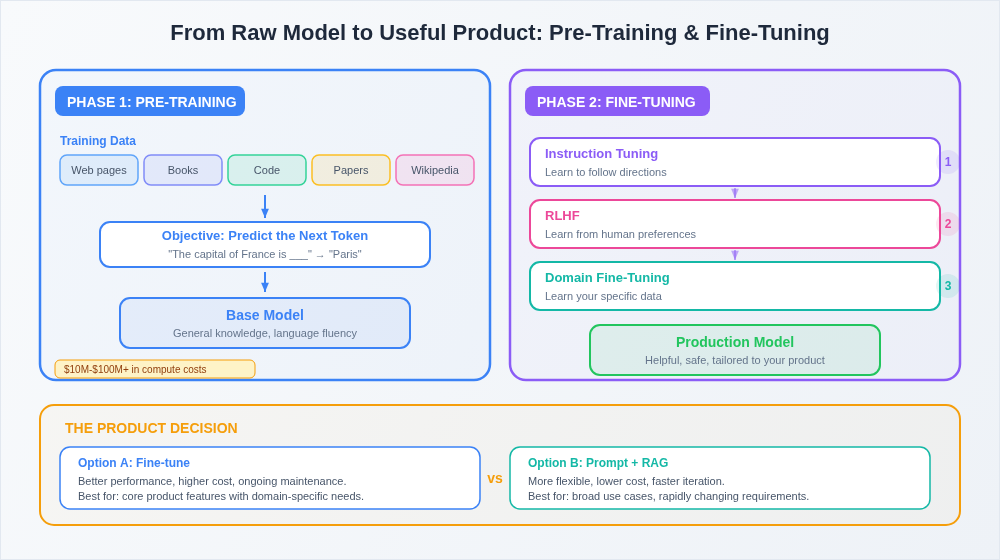
Pre-training is the first phase of building an LLM, and it's conceptually simple: the model reads an enormous amount of text and learns to predict the next token. Give it "The product roadmap needs to be," and it learns that "updated" or "reviewed" or "prioritized" are likely next tokens, while "refrigerator" is not.
When I say "enormous amount of text," I mean it. Models like GPT-4, Claude, and Gemini are trained on datasets that include significant portions of the public internet, plus books, academic papers, code repositories, and more. We're talking trillions of tokens.
Through this process, the model develops what you might call a general understanding of language, knowledge, and reasoning. It learns grammar, facts, writing styles, coding patterns, logical relationships, and much more — all from the single objective of predicting what comes next. This is remarkable when you think about it. Nobody teaches the model that Paris is the capital of France. It learns this because, across billions of text examples, that pattern appears consistently enough for the model to encode it in its weights.
Here's the product-relevant insight: pre-training is astronomically expensive. We're talking tens to hundreds of millions of dollars in compute costs for a frontier model. This is why only a handful of companies (OpenAI, Anthropic, Google, Meta, and a few others) train foundation models from scratch. This cost structure is what created the API-based business model that most product teams interact with. You're not building the foundation, you're building on top of it.
Fine-Tuning: From "Knows Everything" to "Does What You Need"
A pre-trained model is impressive but not immediately useful for most product applications. It can complete text fluently, but it doesn't know how to follow instructions, have a conversation, or behave in the specific way your product needs.
This is where fine-tuning comes in, and if you read the first post, you'll recognize this as transfer learning applied to LLMs. You take the pre-trained model (with its general knowledge baked into billions of weights) and train it further on a smaller, more targeted dataset.
There are a few flavors of fine-tuning that matter for product people:
Instruction tuning trains the model to follow directions. Instead of just predicting the next word, the model learns to respond to prompts like "summarize this document" or "write a SQL query that returns..." This is what transforms a raw text predictor into something that actually feels like an assistant.
RLHF (Reinforcement Learning from Human Feedback) — which I touched on in the first post — is the process that makes models helpful, harmless, and honest. Human evaluators rank model outputs, and those rankings become the training signal. This is why ChatGPT felt like such a leap when it launched. The underlying language model had existed for a while. RLHF is what made it usable.
Domain-specific fine-tuning is where it gets relevant for your product. You can take a foundation model and fine-tune it on your company's data (your support tickets, your documentation, your codebase) to create a model that's fluent in your domain. This is a spectrum, not a binary. Some teams fine-tune aggressively. Others get surprisingly far with clever prompting and retrieval-augmented generation (feeding relevant context into the prompt at inference time, rather than baking it into the weights) that make foundation models more than capable of delivering excellent outputs.
The product decision you'll face repeatedly: should we fine-tune, or should we get creative with prompting and context? Fine-tuning gives you better performance but costs more and requires ongoing maintenance. Prompting is more flexible but hits a ceiling (though that ceiling is increasingly raising with every foundation model release). There's no universal answer, but understanding the trade-off is table stakes.
Context Windows: The Constraint You'll Hit Every Day
Remember how I mentioned that LLMs can only process a finite number of tokens at once? That limit is called the context window, and it's one of the most practical constraints you'll deal with as a PM building with LLMs.
Early GPT models had a context window of about 2,000 tokens — roughly 1,500 words. Current models range from 128,000 to over a million tokens. That sounds like a lot, and it is, but it goes faster than you think.
Here's why this matters: the context window includes everything. The system prompt that defines how the model behaves in your product? That's eating into the context window. The user's conversation history? Context window. The documents you're feeding in for summarization? Context window. The model's own response? Also context window.
When you run out of context, the model can't see the information anymore. It's not that it forgets in the way humans forget. It literally cannot access tokens that fall outside the window. This has direct product implications. If your user is having a long conversation with your AI assistant, earlier messages start falling out of the window. If your document is longer than the context window, you can't just feed the whole thing in. You need a strategy — chunking, summarization, retrieval-augmented generation — to work within this constraint.
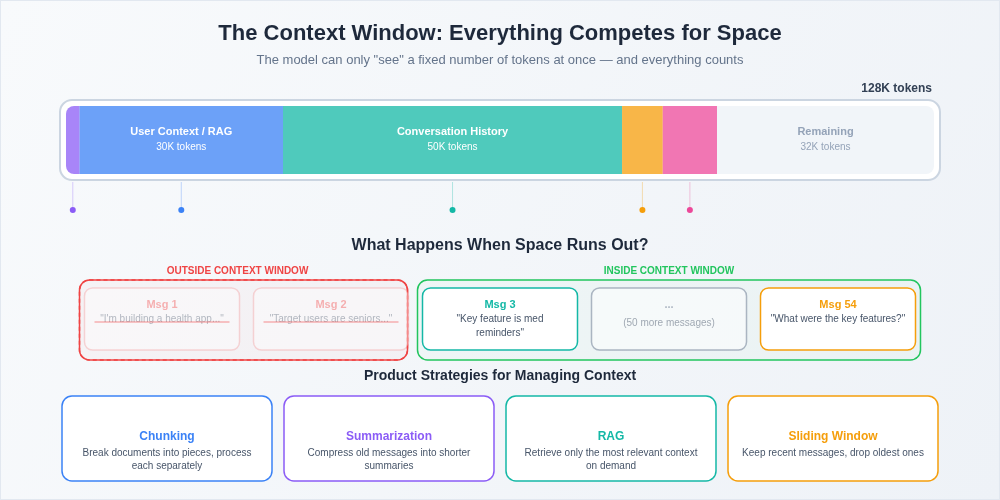
Think of the context window like working memory. You can hold a certain amount of information in active use at any given time. When you need to reference something outside that active set, you need a system for looking it up. Products that handle this well feel magical. Products that don't leave users wondering why the AI "forgot" what they said five minutes ago.
Hallucinations: Why the Model Makes Things Up
This is the one every PM building with LLMs needs to deeply understand, because it's the single biggest trust issue your users will encounter.
LLMs hallucinate. They generate text that is fluent, confident, and completely wrong. They'll cite papers that don't exist. They'll invent statistics. They'll confidently describe a feature your product doesn't have. And they do it in the exact same tone as when they're being accurate, which makes it genuinely dangerous.
Why does this happen? Because of what the model is fundamentally doing: predicting the most likely next token. The model isn't "looking up" facts from a database. It's generating text that patterns like accurate text, based on the statistical relationships it learned during training. Most of the time, that produces correct information. But the model has no internal mechanism for distinguishing "I know this is true" from "this sounds like it should be true."
Here's an analogy. Imagine a colleague who's read every document in your company wiki and has a phenomenal memory for patterns. You ask them a question about a specific policy, and they give you an answer that sounds exactly right with confident tone, correct terminology, and proper context. But they're not checking the wiki. They're reconstructing what a correct answer would sound like based on everything they've read. Most of the time they're right. Sometimes they're plausibly wrong.
This is not a bug that will be fully "fixed" in the next model version. It's a fundamental characteristic of how these systems work. Better models hallucinate less, but the tendency is inherent to the architecture.
The product implications are significant. Any feature where accuracy matters (and let's be honest, that's most features) needs a strategy for handling hallucinations. That might mean retrieval-augmented generation (grounding the model's responses in actual source documents), output validation, confidence scoring, human-in-the-loop review, or UX patterns that set appropriate user expectations. The worst thing you can do is ship an LLM feature that presents generated text as authoritative fact without any guardrails.
Why This Matters for Product People
If you've been following along from the first post, you now have a working mental model of the full stack: from basic neural network mechanics to how LLMs specifically process language, learn from data, and generate responses.
Here's why this matters practically:
When your team debates context window limits, you understand why the constraint exists and can make informed trade-offs between conversation depth, context injection, and cost. When a stakeholder asks "why can't the AI just remember everything," you can explain the architecture in terms they'll grasp.
When you're evaluating model providers, you understand that the differences between models aren't just "this one is smarter." They reflect different training data, different fine-tuning approaches, different attention architectures, and different trade-offs between capability, cost, and safety.
When a user reports that the AI "lied" to them, you understand that hallucination isn't a quality issue your engineering team can just fix, it's an architectural characteristic that requires a product-level strategy.
And when someone on your team proposes fine-tuning versus prompt engineering versus RAG, you can participate in that conversation as a genuine partner, not a spectator nodding along to technical jargon.
That's the goal of this series. Not to make you an ML engineer. To make you a product leader who can reason clearly about the most important technology of your career.
Next up in the series: we'll tackle the concept everyone's buzzing about right now: agents. What they actually are, how they're built on top of the LLM foundations we just covered, and the agentic patterns that are reshaping how we think about product development. Because understanding how LLMs work is step one. Understanding what happens when you give them tools, memory, and the ability to take actions on behalf of your users? That's where things get really interesting.



