
What Makes an AI Agent an Agent (And When It's Just a Chatbot in a Trench Coat)


Beyond the Backlog, AI Deep Dive, Part 3
In the first post, we cracked open deep learning: nodes, layers, weights, backpropagation, and the fundamental machinery that lets neural networks learn from data. In the second, we zoomed into large language models: transformers, attention, context windows, and the mechanisms that make LLMs remarkably capable at working with language.
I ended that post with a teaser: what happens when you give an LLM tools, memory, and the ability to take actions on behalf of your users?
Now we find out!
If you've been on LinkedIn in the last six months, you've seen the word "agent" slapped onto every product announcement, pitch deck, and startup landing page. AI agents for sales. AI agents for support. AI agents for your grocery list. Agents for all!
But here's the thing: most of what people call "agents" aren't agents. They're chatbots with better marketing. So let's cut through the noise. What actually makes an agent an agent? How does the architecture work under the hood? And when should you, as a product person, actually reach for this pattern versus something simpler?
From Text Generator to Action Taker

Let's start with what you already know from the last two posts.
An LLM, at its core, predicts the next token. You give it text, it generates more text. It does this extraordinarily well, well enough to summarize documents, write code, and answer complex questions. But at the end of the day, it's generating text. It's not doing anything in the world.
An agent changes that equation in a way that matters: it acts.
Not "generates text about acting." Actually takes actions. An agent can look at a goal, break it into steps, decide which tools to use, execute those steps, observe the results, and adjust its approach, all without you holding its hand through every move. Anthropic has a great definition that Agents "are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks" (See Building Effective AI Agents for a great overview of different agentic design patterns).
Here's an analogy. An LLM is like texting a really smart colleague. You ask a question, you get an answer. An agent is like delegating a task to a capable junior PM. You say "pull together the competitive analysis for our quarterly review," and they figure out what data to gather, which tools to use, what structure makes sense, and come back with a deliverable. They might hit a dead end and pivot. They might ask you a clarifying question when they genuinely need your input. But they're driving the work, not just answering questions about it.
The Reasoning Loop: Think, Act, Observe
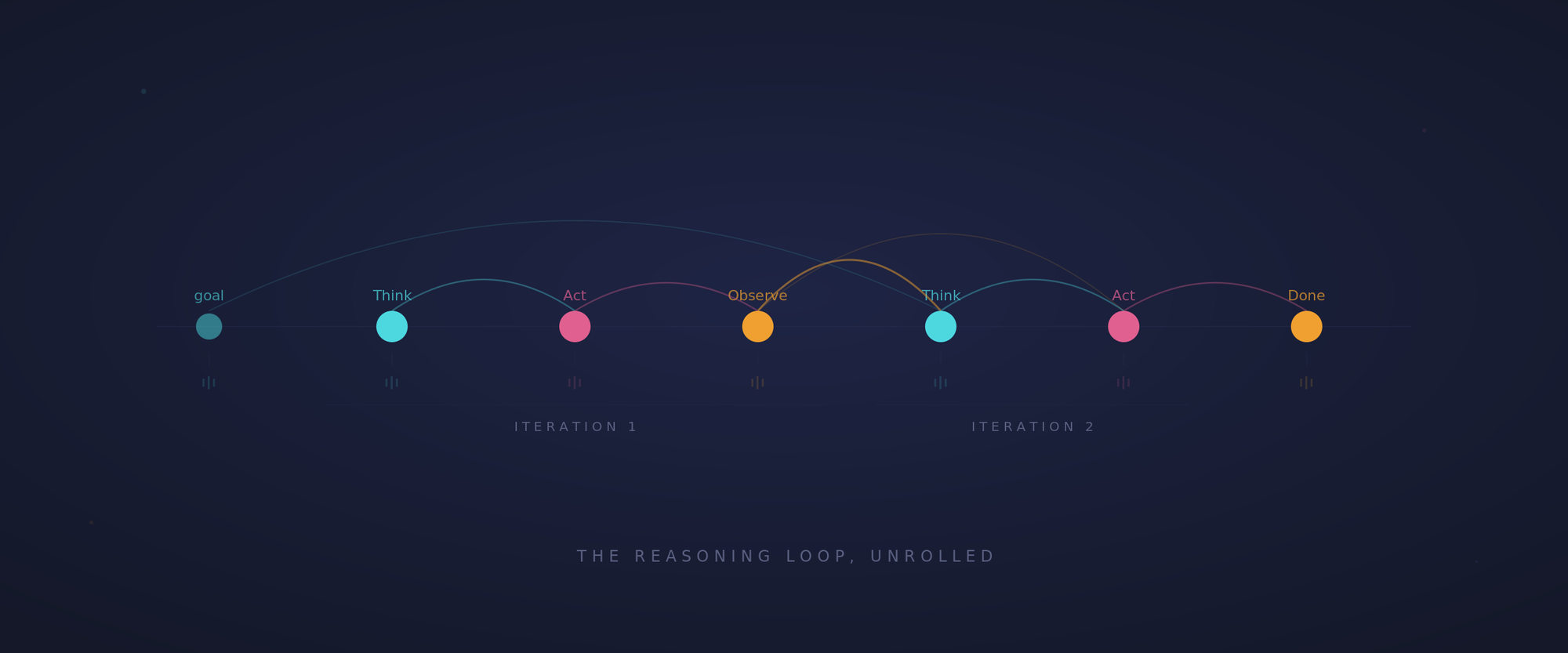
Under the hood, agents run on what the AI world calls a reasoning loop. The most common pattern is called ReAct (Reason plus Act). It works like this:
Think. The model looks at the current situation (the goal, what it knows so far, what's happened in previous steps) and reasons about what to do next.
Act. Based on that reasoning, it takes a specific action. This might be calling an API, searching the web, querying a database, writing to a file, or invoking any other tool or sub-agent it has access to.
Observe. It examines the result of that action. Did it get what it needed? Was the data what it expected? Did something go wrong?
Then it loops back to Think, incorporating what it just learned.
This is the fundamental architectural difference. An LLM generates one response and stops. An agent runs a loop (think, act, observe, repeat) until the task is complete or it determines it's stuck, all while making use of tools and sub-agents to accomplish its overall task.
Think of it like the difference between a GPS that gives you directions at the start of your trip versus one that's actively monitoring traffic, rerouting you around an accident, and suggesting a gas stop based on your fuel level. Both use maps. Only one is actually navigating.
If you remember backpropagation from the first post, the cycle of forward pass, calculate loss, adjust weights, repeat, the reasoning loop is a conceptual cousin. It's a system that iteratively improves toward a goal. The difference is that backpropagation happens during training across millions of examples. The reasoning loop happens at inference time, in real time, on a single task.
Tool Use: Giving the Brain Hands
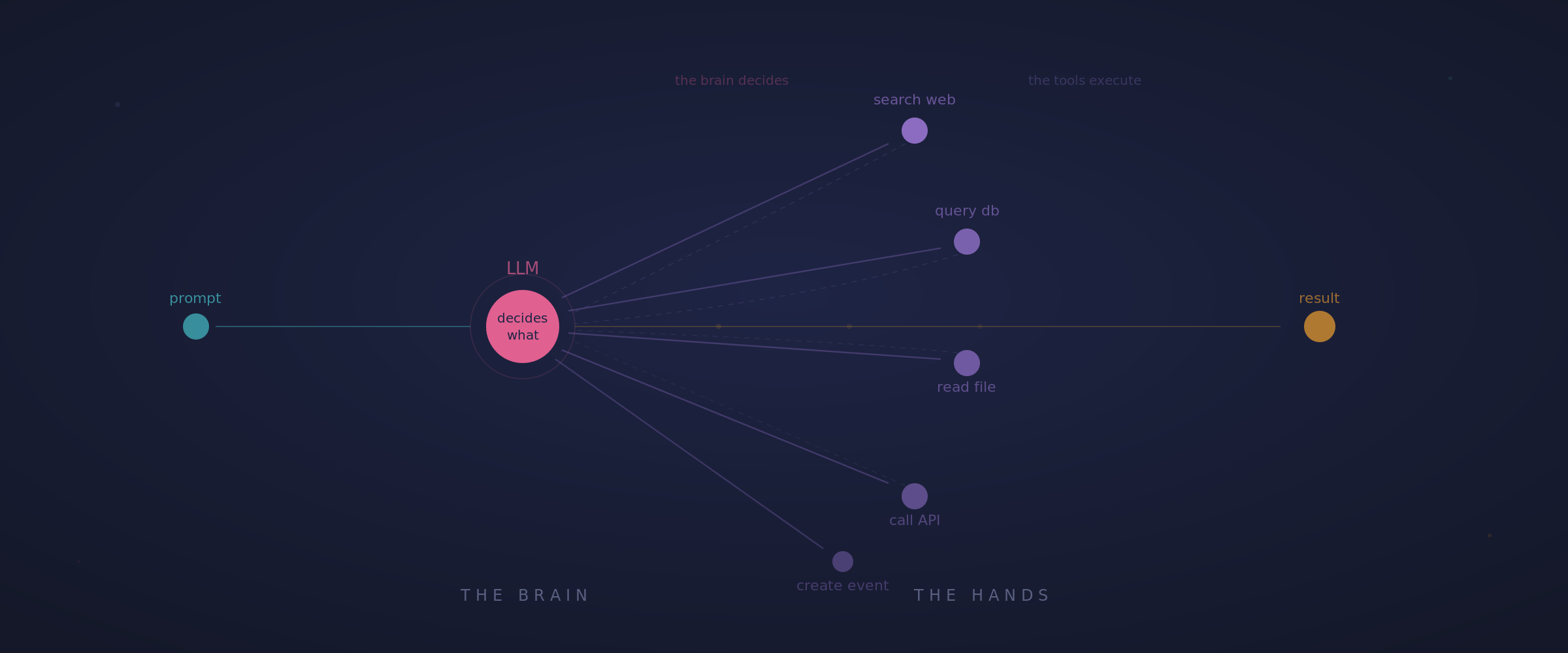
Here's a key concept that connects directly to what we covered about LLMs: the model itself can only generate text. That's all the transformer architecture produces. Tokens in, tokens out.
What gives an agent the ability to act in the world is tool use, sometimes called function calling. The model gets a structured menu of tools it can invoke: "search the web," "read this file," "create a calendar event," "query this database," "send this message." When the model decides it needs information or needs to take an action, it generates a structured call to one of these tools. The tool executes, returns a result, and the model incorporates that result into its next reasoning step.
Where things get really cool is that these tools can also be agents, commonly called "sub-agents." If an agent calls a sub-agent, that sub-agent has access to its own set of tools, has its own discrete task as passed on to it by the parent agent, and will run its own reasoning loop until it accomplishes its task. Chaining together parent orchestrator agents with sub-agents is a powerful way to build agentic systems.
This is the unlock that turns a text generator into something that interacts with real systems. Think of the LLM as the brain and the tools as the hands. The brain decides what to do. The hands do it. Without tools, you've got a brain in a jar: impressive reasoning ability, but no way to change anything in the real world.
Here's a concrete example. Say you ask an agent to "find all the bugs filed this week that are tagged as P1 and draft a summary for my team standup." The agent might:
- Call the Jira API to query for P1 bugs from the last 7 days
- Read through the results and identify patterns (three bugs in the checkout flow, two in the API layer)
- Realize it needs more context on the checkout bugs, so it pulls up the related tickets
- Draft a summary that groups the issues by area and highlights the most critical ones
- Format it for Slack and present it for your review
No single step here is revolutionary. But the agent decided the sequence, adapted when it needed more context, and drove the task to completion. That's the reasoning loop plus tool use working together.
What "Thinking Agentically" Means for Product Design
Agentic thinking isn't just about understanding the technology. It's about recognizing a fundamentally different design pattern for how software can work.
Traditional software is procedural. You define every step, every branch, every edge case. If this, then that. The logic is deterministic: same input, same output, every time. This is how most of the software we build works, and it works well for the vast majority of use cases.
Agentic software is goal oriented. You define what you want accomplished, and the system figures out how. The path might be different every time. The agent might try one approach, realize it doesn't work, and pivot to another, just like a human would.
This changes how you think about several aspects of product design:
Inputs become goals, not commands. Instead of designing a 12 step wizard where the user makes a decision at every stage, you might design a single input where the user describes what they want and the agent figures out the steps. The UX shifts from "guide the user through a process" to "let the user state intent and show them the result."
Error handling becomes adaptive. Instead of predefined error states with hardcoded recovery paths, the agent can recognize when something isn't working and try a different approach. Your API returned a 500? The agent might retry, try a different endpoint, or work around the issue. These are decisions that would normally require engineering logic for every possible failure mode.
Workflows become dynamic. Instead of rigid pipelines where step 3 always follows step 2, you get flexible systems that can handle variation. Two users might ask for the same thing and the agent might take completely different paths to get there, depending on what it discovers along the way.
Evals are a must. Given that much of the "how" is inside the agent's control, having robust evaluation sets is critical to success in building agentically. You need to define your ground truth set and have it run against outputs and different stages of the agent's work to ensure that the results are what you require.
But (and this is a critical "but") this also introduces a new category of product challenges that deserve attention.
When Agents Are the Right Call (And When They're Not)

This is the part that doesn't get enough airtime. Everyone's so busy hyping agents that nobody's talking about when not to use them.
Agents shine when:
The task involves multiple steps and requires judgment along the way. Researching a topic, synthesizing information from multiple sources, triaging and summarizing a backlog of tickets, debugging a complex problem: these are agent territory. The value comes from the reasoning loop. The agent can adapt its approach as it learns more about the problem.
The workflow isn't fully predictable. If you can't map every possible path in advance, because user inputs vary wildly or the right next step depends on what you discover in the previous one, an agent's ability to reason on the fly is a genuine advantage over hardcoded logic.
The cost of imperfection is manageable. Drafting content, summarizing research, generating reports for human review, triaging incoming requests: if the agent gets it 90% right and a human polishes the last 10%, that's a massive productivity win. Relying on a human-in-the-loop backstop creates productivity boosts and end-user confidence when building agentically.
Agents are a bad fit when:
The task needs to be exactly right every time. Financial calculations, legal compliance, medical decisions: anywhere the cost of being wrong is high and the tolerance for variation is zero. Remember from the LLM post: these models hallucinate. Adding a reasoning loop doesn't eliminate that. It can actually amplify it, because errors in early steps compound through the loop.
The workflow is already well defined. If you've got a process that works the same way every time with clear inputs and outputs, traditional automation is simpler, cheaper, and more reliable. You don't need AI reasoning to follow a flowchart. An if/else statement is a better agent than an LLM when the logic is deterministic.
You can't afford the latency or cost. Agents make multiple LLM calls in a loop. Each call costs tokens and takes time. A single agent task might involve 5, 10, or 20 LLM calls before it's done. For high volume, low margin tasks, the economics might not work. This is a real constraint that the hype conveniently glosses over.
Transparency is non-negotiable. Agents can be opaque. The reasoning loop makes it hard to explain why the agent took the path it did, especially when it pivoted mid-task. If your users or regulators need a clear audit trail showing exactly why a decision was made, that's a genuine architectural constraint you need to design around.
A simple LLM or prompt chaining will get you what you need. LLMs are very powerful! And you can easily design systems that conditionally chain prompts together. When more determinism is needed, cost is a concern, or this method will get you what you need, it's preferable to build without an agent.
Cutting Through the Hype
Let me be direct: the agent hype cycle is running hot, and a lot of what's being labeled "agentic" doesn't deserve the term.
A wrapper around ChatGPT with a system prompt is not an agent. A workflow that's hardcoded with an LLM generating text at each step isn't an agent either. It's automation with an LLM in the middle. There's nothing wrong with either of these patterns, but calling them "agents" muddies the water and sets wrong expectations.
A real agent reasons, acts, observes, and adapts while using tools. It exercises judgment about what to do next based on what just happened. The key word is autonomy: the system is making decisions about its own execution path, not just following a predetermined sequence.
That said, real agents are here, and they are getting remarkably capable. Code agents that can navigate a codebase, write implementations, run tests, observe failures, and debug their own errors. Research agents that can search the web, evaluate sources, synthesize findings, and produce structured reports. Customer service agents that can resolve complex issues from start to finish by interacting with real backend systems.
The technology is real. The question for product people isn't "should we use agents?" It's "where in our product do agents create genuine value, and where are we just chasing a trend?"
Why This Matters for Product People
If you've been following this series, you now have a working mental model of the full stack: from how neural networks learn, to how LLMs process language, to how agents use those capabilities to reason and act autonomously.
Here's how to put it to work:
When someone on your team proposes "adding agents" to your product, you can ask the right questions. What's the reasoning loop? What tools does the agent have access to? Where can we use sub-agents? Where does a human stay in the loop? How do we determine when to bail out to that human in the loop? What happens when the agent goes down an unproductive path? These aren't engineering questions. They're product questions.
When you're designing the UX for agentic features, you understand that the challenge isn't just the final output. It's the intermediate steps. How do you show the user what the agent is doing? How do you let them course correct? How do you build trust when the system is making autonomous decisions? This is a genuinely new UX design space, and the teams that figure it out first will have a significant advantage.
And when a stakeholder asks "why can't we just have an AI agent handle all of this?" you can give a nuanced answer grounded in architectural reality. Sometimes the answer is "we can, and here's how." Sometimes it's "we could, but the cost and reliability tradeoffs don't make sense for this use case." Both answers are more valuable than either unbounded enthusiasm or reflexive skepticism.
The most effective AI product leaders I know are the ones who understand the technology well enough to match the right tool to the right problem. Neural networks for pattern recognition. LLMs for language understanding and generation. Agents for complex, judgment intensive tasks that benefit from autonomous reasoning.
Understanding how these systems actually work won't give you all the answers. But it'll make sure you're asking the right questions. And in product, that's usually what matters most!



