
Vector Databases, Embeddings, and RAG: Giving LLMs the Context They're Missing

In a prior post, we broke down how large language models actually work — tokenization, embeddings, transformers, context windows, and hallucinations. If you haven't read that one yet, go do that first. This builds directly on it.
Here's the key takeaway from that post: LLMs are incredibly powerful general-purpose reasoning engines. They've absorbed patterns from enormous swaths of the internet. They can write, summarize, analyze, and generate with remarkable fluency.
But they don't know anything about your business.
They don't know your internal policies. They haven't read your product documentation. They can't reference the contract your legal team signed last quarter or the support ticket your biggest customer filed yesterday. And when you ask them about this stuff, they don't say "I don't know." They confidently generate something that sounds right. They predict plausible next tokens based on patterns, not facts.
This is the gap that kills most enterprise AI implementations. The model is smart but uninformed. And the solutions to that gap — embeddings, vector databases, and retrieval-augmented generation — are some of the most important concepts for product people to understand right now.
Embeddings: A Quick Recap, Then the Part That Matters Here
We covered embeddings in the LLMs post, so I'll keep this brief. An embedding is a numerical representation of meaning — a vector (a list of numbers) that captures the semantic essence of a piece of text. Words with similar meanings end up close together in this high-dimensional space. "King" is near "queen." "Churn" is near "attrition." The model learns these relationships during training.
That was the LLM context with embeddings as an internal step in how a language model processes text. Here's what's new and what matters for this post: embeddings are also a standalone tool you can leverage to augment LLM performance.
You can take any piece of text, be it a sentence, a paragraph, or an entire document, and convert it into an embedding vector using a dedicated embedding model. OpenAI has one. Cohere has one. There are excellent open-source options and domain-specific options. The output is the same concept: a list of numbers that represents the meaning of that text.
Why would you do this? Because once you've converted text into vectors, you can do something remarkably useful: you can search by meaning.
Traditional search is keyword-based. If a user searches for "cancellation policy" and your document says "termination procedures," keyword search misses it. They're different words. But their embeddings? They're close together in vector space, because the
meaning is similar. Embedding-based search, also called semantic search, finds content based on what it means, not just what words it uses.
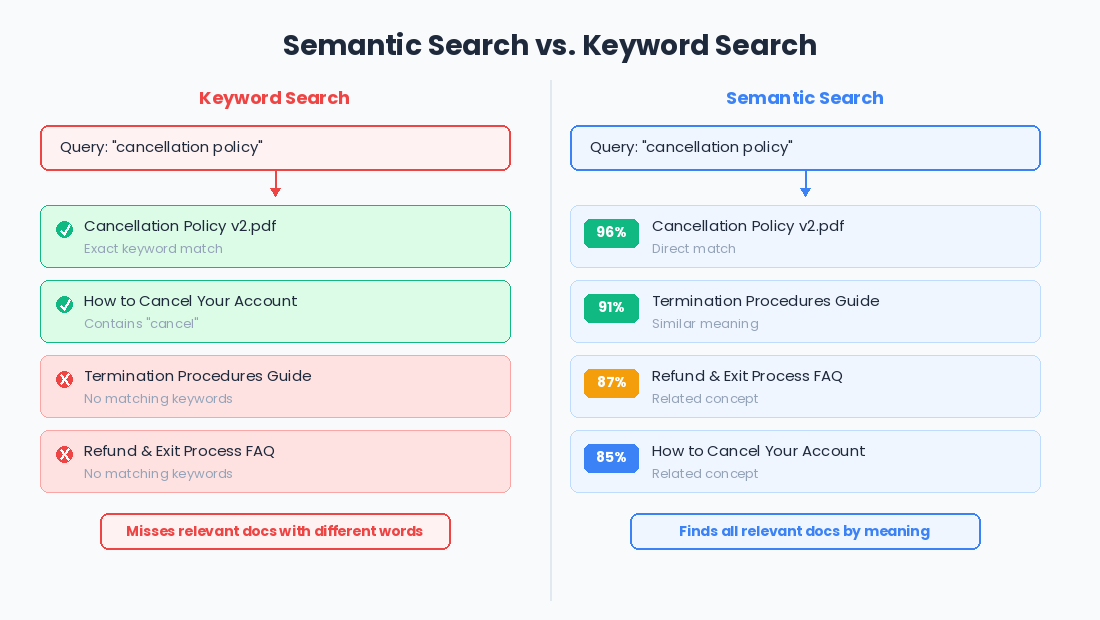
This changes the game for product teams. Think about every search feature you've ever built or used. Now imagine it understood intent instead of just matching strings. That's what embeddings unlock.
Vector Databases: Where Meaning Gets Stored
So you've converted your documents into embedding vectors. Now you need somewhere to put them.
A vector database is exactly what it sounds like: a database optimized for storing and querying vectors. But the "optimized" part is doing a lot of heavy lifting, because searching through vectors is fundamentally different from searching through traditional data.
In a regular database, you're looking for exact matches or ranges with queries like "find all users where status = active" or "find all orders placed after January 1st." These are precise queries with precise answers.
Vector search is about similarity. You're asking: "Here's a vector representing my query. Find me the vectors in this database that are closest to it." Closest meaning most similar in meaning. The math behind this involves concepts like cosine similarity and approximate nearest neighbor search, but the product-level takeaway is simpler: vector databases let you find the most semantically relevant content incredibly fast, even across millions of documents.
The major players in this space, Pinecone, Weaviate, Chroma, Qdrant, pgvector (a PostgreSQL extension), each make different trade-offs around scale, cost, hosting, and integration. If your engineering team is evaluating options, the key questions to ask are practical ones. How much data are we indexing? Do we need real-time updates or is batch processing fine? Are we running this in the cloud or on-prem? What's our latency tolerance?
But here's what I want product leaders to internalize: the vector database isn't the product. It's infrastructure. It's plumbing. The product decision is what you put into it and how you use what comes back out. That's where RAG comes in.
RAG: The Pattern That Makes LLMs Actually Useful for Your Business
Retrieval-Augmented Generation. It's a mouthful, but the concept is elegant and it's probably the most important architectural pattern for product teams building with LLMs right now.
Here's the problem RAG solves: you want your LLM-powered feature to answer questions or perform tasks using your data. You have two basic options.
Option one: fine-tune the model. Take a foundation model and train it further on your data so that the knowledge gets baked into the model's weights. This works, but it's expensive, requires ongoing maintenance as your data changes, and the model can still hallucinate, it's just hallucinating from a slightly better-informed starting point.
Option two: give the model the right context at inference time. Instead of trying to cram your knowledge into the model's weights, you retrieve the most relevant information from your own data and include it directly in the prompt. The model doesn't need to "know" your cancellation policy from training. You just hand it the policy document right when the user asks about it.
That's RAG. And it works in three steps:
Step 1: Index. Take your knowledge base, including documents, FAQs, support articles, product specs, whatever, and convert each chunk into embedding vectors. Store them in a vector database. This is a one-time setup (plus ongoing updates as your content changes).
Step 2: Retrieve. When a user asks a question, convert their query into an embedding vector and search the vector database for the most similar chunks. This returns the most semantically relevant pieces of your knowledge base.
Step 3: Generate. Take those retrieved chunks and include them in the prompt to the LLM, along with the user's original question. The model now has the relevant context it needs to generate an accurate, grounded response. Instead of making things up, it's synthesizing from actual source material.
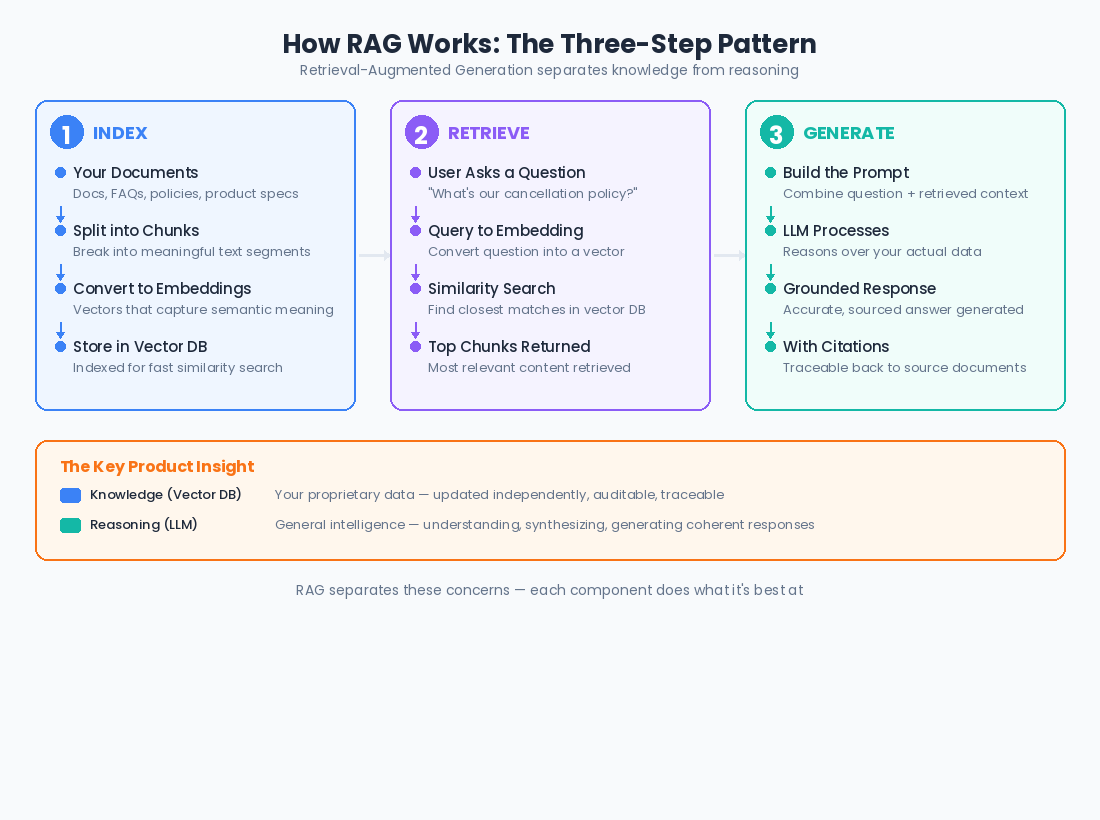
The beauty of this pattern is that it separates knowledge from reasoning. The LLM provides the reasoning capability by understanding the question, synthesizing information, and generating a coherent response. Your vector database provides the knowledge — the actual facts, policies, and content specific to your domain. Each component does what it's best at.
Why RAG Beats Fine-Tuning for Most Product Teams
I mentioned this trade-off in the LLMs post, but it's worth diving deeper because it's a decision you'll face repeatedly.
Fine-tuning is powerful when you need to change how the model behaves in its tone, its format, and its domain-specific reasoning patterns. If you need the model to write like a lawyer or respond in a specific clinical format, fine-tuning might make sense.
But if your primary need is getting the model to reference specific, up-to-date information? RAG wins almost every time. Here's why.
Your data changes. Fine-tuning bakes knowledge into model weights. When your documentation gets updated, your pricing changes, or your product ships new features, you'd need to re-fine-tune. RAG just needs an updated index. Swap out the documents, re-embed the new content, and the model immediately has access to current information.
RAG is auditable. When a RAG system generates a response, you can trace it back to the specific source documents that informed it. You can show users where the answer came from. Try doing that with a fine-tuned model and you face a near-impossible challenge because the knowledge is distributed across billions of weights with no clear attribution.
Cost and maintenance. Fine-tuning a model is expensive and requires ML expertise. Maintaining a RAG pipeline is engineering work, but it's more traditional engineering work involving indexing documents, managing a database, and tuning search relevance. Most product engineering teams can build and maintain a RAG system. Most cannot maintain a fine-tuning pipeline.
They're not mutually exclusive. Some of the most effective implementations combine both with a fine-tuned model for domain-specific behavior paired with RAG for domain-specific knowledge. But if you're starting out and picking one approach? Start with RAG. You'll get much further, much faster.

The Product Decisions That Actually Matter
Here's where I want to shift from "how it works" to "what you need to care about," because the technical mechanics of RAG are the easy part. The product decisions are where things get interesting.
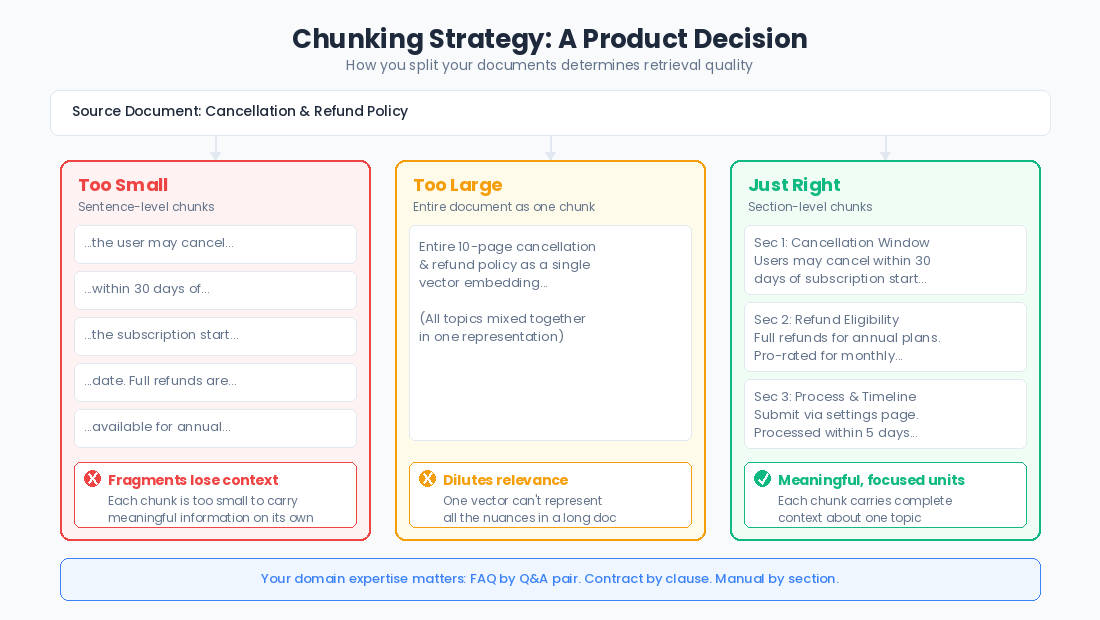
Chunking strategy. Before you embed your documents, you need to break them into chunks. How big should those chunks be? Too small and you lose context. A sentence fragment doesn't carry much meaning on its own. Too big and you dilute relevance. A ten-page document embedded as a single vector won't surface for specific questions. The right chunk size depends on your content and your use case, and it's one of the highest-leverage tuning decisions you'll make.
This is a product decision, not just a technical one. You need to understand your content well enough to know what constitutes a meaningful unit. For a FAQ, each question-answer pair is a natural chunk. For a legal contract, maybe it's clause by clause. For support documentation, it might be section by section. Your domain expertise matters here.
Retrieval quality is your ceiling. Here's something I wish more product people understood: the quality of your RAG system is bounded by the quality of your retrieval. If the wrong documents get pulled from the vector database, it doesn't matter how capable the LLM is, it's generating from bad context. Garbage in, garbage out, but with the confident tone of an LLM.
This means investing in retrieval quality is probably more important than debating which LLM to use. Better embeddings, better chunking, better metadata filtering, and hybrid search (combining semantic and keyword search) are the unglamorous improvements often have a bigger impact on user experience than upgrading to a more expensive model.
Grounding and citations. One of RAG's superpowers is that you can cite your sources. When the model generates a response from retrieved documents, you can show users which documents informed the answer. This is huge for trust, especially in high-stakes domains. But it's not automatic — you need to design for it (shoutout to the importance of UX in AI products, it's fundamental!). The UX around citations, source links, and confidence indicators is a product design challenge that deserves real attention.
Failure modes. RAG systems fail differently than vanilla LLMs, and you need to design for these failure modes explicitly. What happens when the retrieval returns nothing relevant? The model might fall back to its general knowledge and hallucinate. What happens when the retrieved content is outdated or contradictory? The model might generate a confused or inaccurate response. Your product needs guardrails for these scenarios. Those could be confidence thresholds, fallback behaviors, or explicit "I don't have enough information to answer this" responses.
Context Windows and RAG: The Practical Tension
Remember context windows from the last post? They create a real constraint for RAG systems that product teams need to navigate.
Every token of retrieved context you inject into the prompt is eating into the context window. More context generally means better answers, but only up to a point. But there's a ceiling on how much you can include, and you're also competing with the system prompt, the conversation history, and the space the model needs for its response.
This creates a retrieval budget. You can't just dump every vaguely relevant document into the prompt. You need to be selective by retrieving the most relevant chunks, in the right order, within a reasonable token budget. Getting this balance right is an ongoing tuning exercise, and it directly affects how good your product feels to use.
Some teams get clever here with techniques like re-ranking (using a separate model to sort retrieved results by relevance before injecting them), or summarizing retrieved chunks to compress the context. These are worth knowing about because they're the kinds of improvements that turn a "pretty good" RAG implementation into something that genuinely delights users.
Why This Matters for Product Leaders
If you're building any product feature that needs to work with proprietary data (and in an enterprise context, that's essentially every feature), you need to understand RAG. Not at the "I can implement it" level. At the "I can make informed decisions about it" level.
When your engineering team proposes a RAG architecture, you should be able to ask: What's our chunking strategy and why? How are we measuring retrieval quality? What happens when the retrieval misses? How are we handling content updates?
When a stakeholder asks why the AI sometimes gets things wrong despite having access to "all our data," you should be able to explain that retrieval quality, chunking, and context window constraints are real engineering challenges, not just bugs to be fixed.
When you're evaluating build vs. buy for your knowledge base features, you should understand what you're actually buying: embedding models, vector storage, retrieval logic, and generation pipelines. Each of these can be swapped, tuned, or replaced independently.
And when someone suggests "let's just fine-tune the model on our data," you should be able to articulate why RAG is probably a better starting point and what specific circumstances might warrant fine-tuning instead.
That's the goal here. Not to make you an ML engineer. To give you enough depth to be a genuine partner in these decisions and to build products that actually work the way your users need them to.



